
Google may not penalize weak pages in a way you can easily see. It may simply stop giving them crawl attention, leave them outside the index, and prevent them from supporting the search and AI visibility path your business depends on.
Many websites are now seeing more URLs appear as “Crawled – currently not indexed” or “Discovered – currently not indexed” in Google Search Console. For low-value pages, this may be normal. For important service pages, product pages, category pages, location pages, comparison pages, and strategic articles, it can become a direct visibility problem.
This is where crawl efficiency becomes important. The goal is not to make Google crawl every URL. The goal is to help Google spend more attention on the URLs that matter most.
Google’s Google Search Console Page Indexing report explains that not every non-indexed URL is necessarily a problem, and that some URLs may remain outside the index for valid reasons. It also defines “Crawled – currently not indexed” as a page Google crawled but did not index, and “Discovered – currently not indexed” as a page Google found but has not crawled yet.
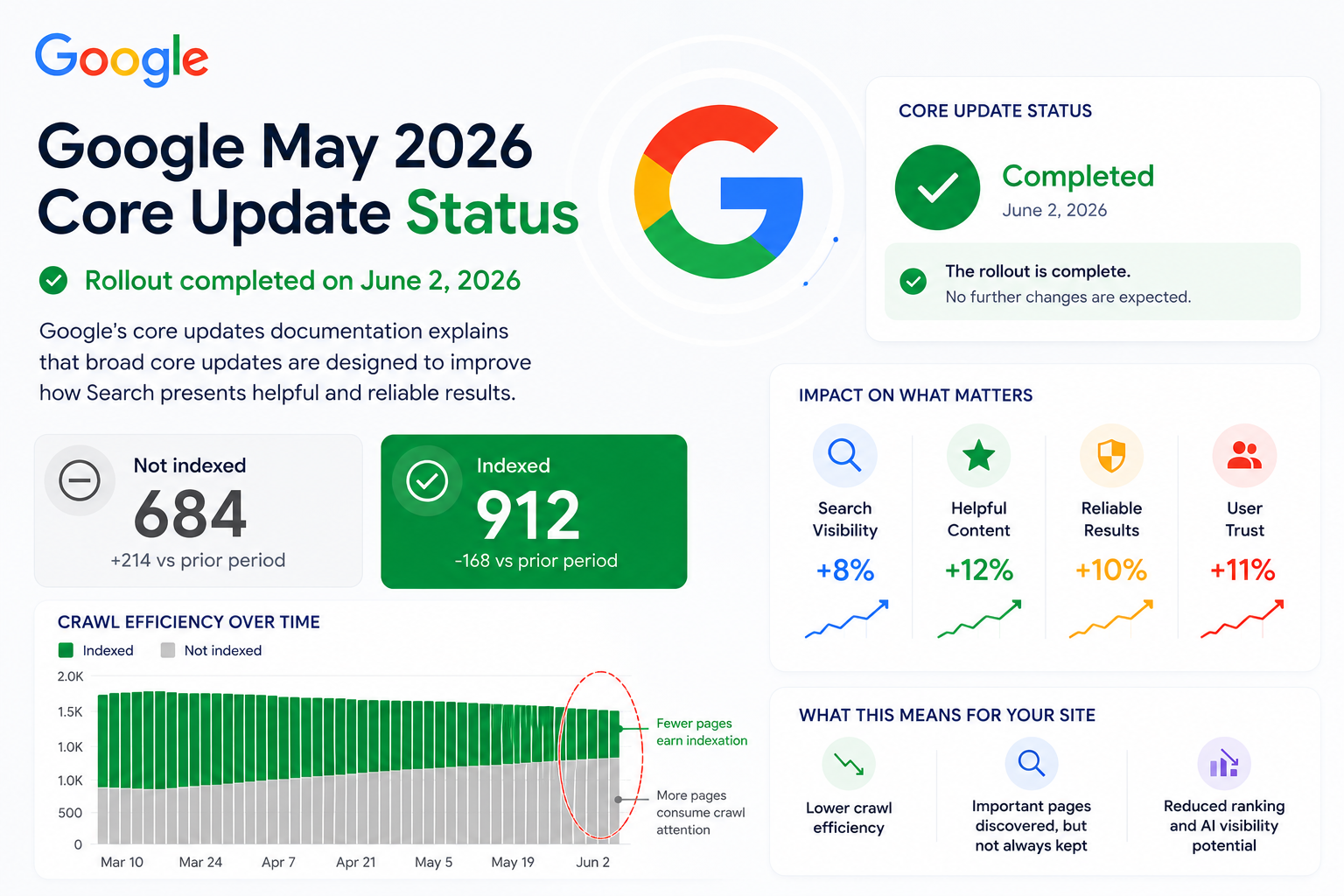
The Google May 2026 core update status confirms that the rollout completed on June 2, 2026. Google’s core updates documentation explains that broad core updates are designed to improve how Search presents helpful and reliable results.
For SEO agencies, ecommerce teams, SaaS companies, publishers, large website owners, and technical SEO teams, the question is no longer only: “How do we get more pages indexed?” The better question is: “Which pages deserve Google’s attention, and which URLs are wasting it?”
See our webinars for a practical walkthrough, or sign up with a free account to get started.
Google Search Console Crawled Currently Not Indexed: Start With Business Value
The phrase Google Search Console crawled currently not indexed describes a common reporting problem: Google has already fetched the page, but the page was not added to the index.
That status should not automatically create panic. Google may crawl a page and decide not to index it because it is duplicate, thin, outdated, unclear, poorly linked, technically inconsistent, or not useful enough compared with other available pages.
The first step is business classification. A non-indexed tag page may not matter. A non-indexed cart page may not matter. A duplicate filter page may not matter. But a non-indexed product category, service landing page, local page, pricing page, or strategic article may create a real business risk. Use this classification before making changes:
- Priority 1: Revenue and conversion pages — service pages, product pages, category pages, comparison pages, pricing pages, demo pages, and lead-generation landing pages.
- Priority 2: Authority and education pages — guides, tutorials, FAQs, research articles, case studies, help content, and topical support pages.
- Priority 3: Utility pages — legal pages, login pages, account pages, internal search pages, thank-you pages, and operational pages.
- Priority 4: Crawl-noise pages — duplicate filters, thin tags, sort URLs, parameter variations, expired listings, empty categories, and soft 404 patterns.
Crawl efficiency starts by separating these groups. A Priority 1 URL deserves diagnosis. A Priority 4 URL may need control, consolidation, or removal from the crawl path.
Google Search Console Discovered Currently Not Indexed: Separate Crawl Delay From Page Rejection
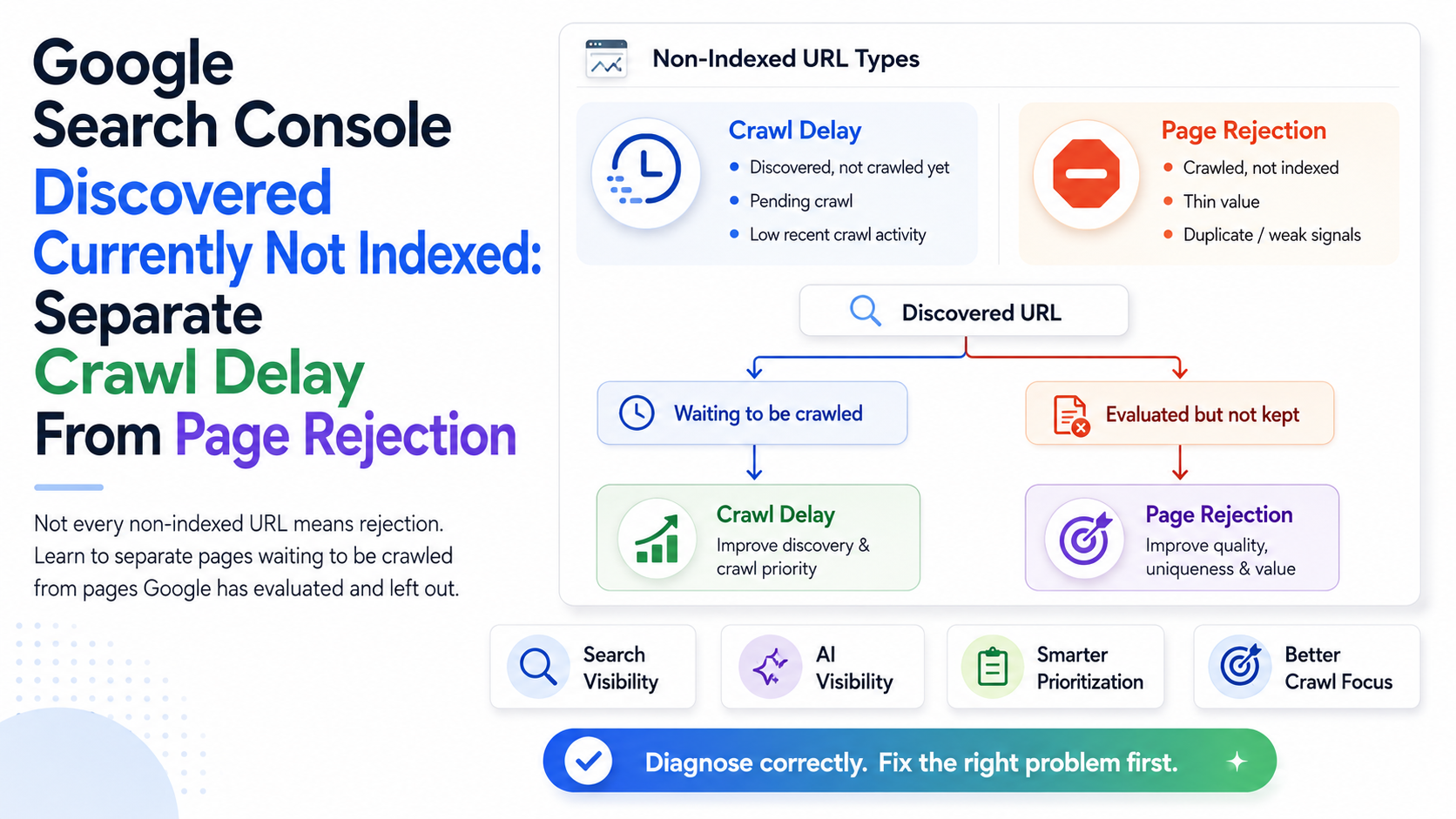
The phrase Google Search Console discovered currently not indexed describes a different issue. Google knows the URL exists, but it has not crawled it yet. This can happen when a URL is found through a sitemap, internal link, external link, feed, canonical reference, or another discovery path, but Google does not allocate crawl resources to fetch it immediately.
The Google Search Console Page Indexing report explains that “Discovered – currently not indexed” means the page was found but not crawled yet, and that Google may reschedule crawling when crawling is expected to overload the site.
This status should be handled differently from “Crawled – currently not indexed.” A crawled URL has already been evaluated at least once. A discovered URL has not yet reached that stage. For discovered URLs, review:
- Internal links
- XML sitemap inclusion
- Server reliability
- Crawl paths
- Duplicate URL patterns
- Canonical consistency
- URL depth
- Page importance
- Low-value URL volume
A discovered URL may not need page-level rewriting yet. It may first need stronger crawl paths and clearer priority signals.
Google Crawl Budget: Reduce URL Noise Before Asking For More Crawling

Google crawl budget is shaped by what Google can crawl and what Google wants to crawl. Google’s crawl budget documentation explains that crawl budget is determined by crawl capacity and crawl demand. Crawl demand can be influenced by site size, update frequency, page quality, relevance, perceived inventory, popularity, and staleness.
This is why crawl efficiency is not only a technical SEO issue. It is also an inventory-quality issue. If a website exposes too many weak URLs, Googlebot has more low-value paths to process. That can reduce the relative attention given to the pages that actually support rankings, leads, sales, and AI visibility.
Common crawl-noise patterns include:
- Ecommerce filter combinations that create near-identical category URLs
- Tag pages that repeat the same posts with little or no unique value
- Location pages that only swap city names without local relevance
- Outdated documentation pages that no longer match the current product
- Expired listings that return thin content instead of clear status handling
- Internal search result pages exposed to crawlers
- Parameter URLs that multiply the same content across many variations
The answer is not always to block everything. The correct action depends on the page type. Some URLs should be canonicalized. Some should be noindexed. Some should be blocked from crawling. Some should be redirected. Some should be improved. Some should be removed. A better crawl efficiency strategy reduces the noise before requesting more crawling.
Discovered Currently Not Indexed What To Do: Build A Priority Queue
Many teams ask discovered currently not indexed what to do after exporting a long list from Google Search Console. The answer is not to request indexing for every URL. Start by building a priority queue. For each URL, ask five questions:
- Does this URL support revenue, leads, authority, product discovery, or brand visibility?
- Is the URL linked from important pages?
- Is the URL included in the correct XML sitemap?
- Does the page provide unique content that deserves crawl attention?
- Is the URL competing with many duplicate or near-duplicate variations?
Then assign each URL to one of four action groups:
- Improve — when the page is important but weak. Improve the content, metadata, internal links, structured data alignment, and page relevance.
- Connect — when the page is valuable but poorly linked. Add internal links from related pages, navigation modules, breadcrumbs, category pages, and relevant articles.
- Consolidate — when several URLs serve the same intent. Merge weak variants into a stronger canonical page.
- Control — when the URL should not consume crawl attention. Use the appropriate combination of canonical tags, robots rules, noindex, redirects, sitemap cleanup, or removal.
This process prevents teams from wasting time on URLs that should never become priority pages.
Fix Crawled Currently Not Indexed: Improve The Page Before Resubmitting
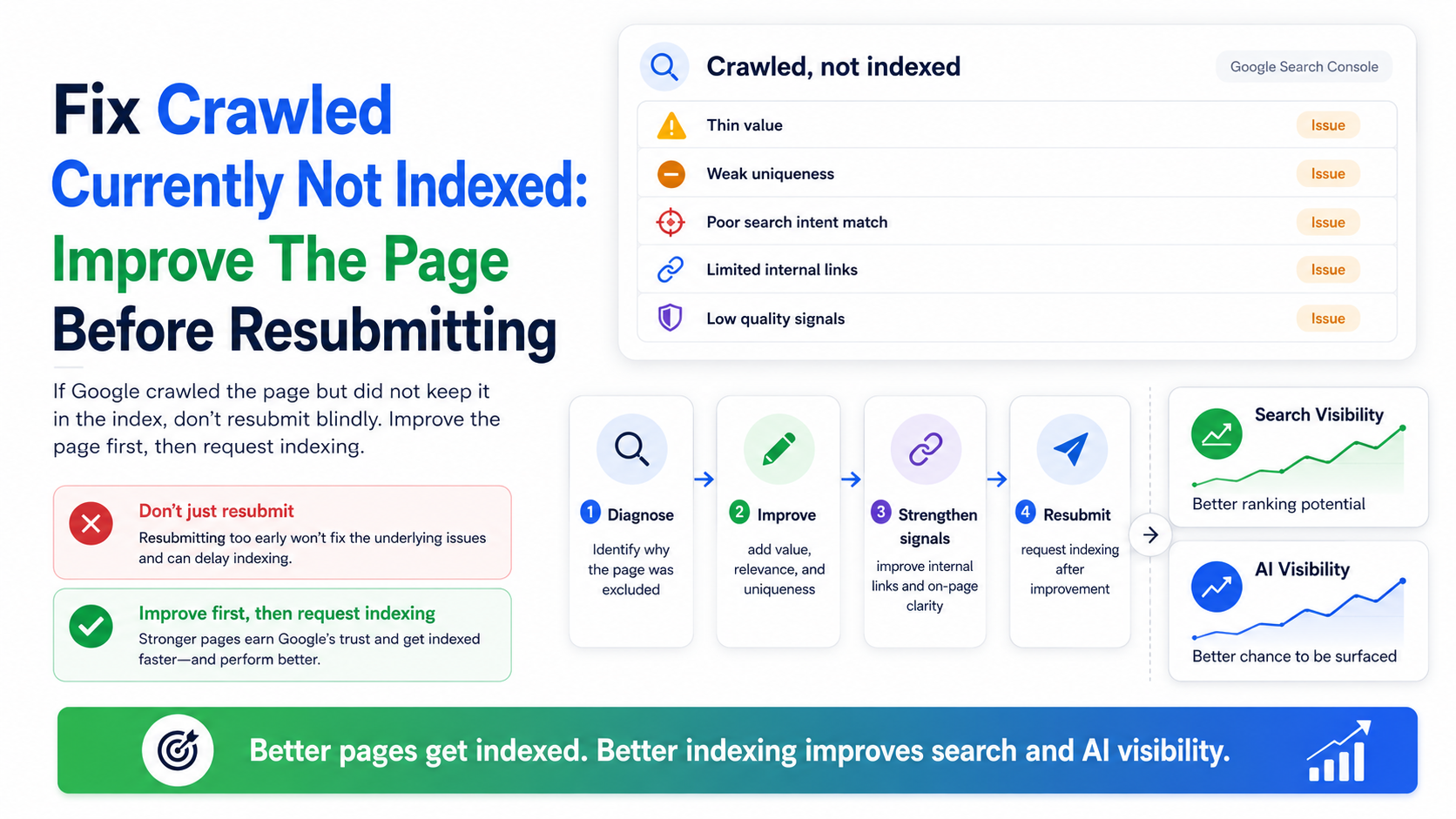
The phrase fix crawled currently not indexed should not mean “click request indexing again.” If Google already crawled the page and did not index it, the page needs a stronger reason to be included.
Start with content value. Does the page answer a clear query? Does it provide original information? Does it offer enough detail? Does it include examples, proof, specifications, FAQs, comparisons, or useful context? Does it satisfy search intent better than other pages already indexed?
Then review page clarity. The title should clearly describe the page topic. The meta description should explain the value of the page. The headings should structure the answer. The visible content should match the intended query. The internal anchor text should reinforce the page purpose. The canonical tag should be consistent. The rendered HTML should expose meaningful content.
For commercial pages, add specificity — clear service details, use cases, proof, FAQs, location relevance, and supporting internal links. For product pages, add unique descriptions, specifications, availability details, reviews, comparisons, media, and structured data that matches the visible content. For category pages, add buying guidance, comparison logic, helpful filters, internal links to important subcategories, and content that makes the page more than a product grid. For articles, improve information gain with clearer explanations, stronger examples, updated details, better structure, and internal links to related content.
No tool can force Google to index a page. The goal is to give Google stronger reasons to crawl, understand, index, and rank the page.
Fix Discovered Currently Not Indexed: Strengthen Crawl Paths And Signals

The phrase fix discovered currently not indexed should start with crawl access and crawl priority. A discovered URL may not have been crawled because it is not important enough within the site structure, because the site exposes too much URL noise, or because Google has limited crawl demand for that part of the site.
Start with the path. Is the page linked from the homepage, category pages, related guides, navigation, breadcrumbs, or other strong pages? If not, the site may be signaling that the page is not important.
Then review the sitemap. Is the URL included in the correct XML sitemap? Is the sitemap clean? Does it include only canonical, index-worthy URLs? Are outdated, redirected, noindexed, duplicate, or low-value URLs still present?
Then review site patterns. If Google discovers thousands of low-value URLs, important discovered URLs may be competing with weak inventory. Improving crawl efficiency may require cleaning the system, not only the page. For example:
- Remove outdated sitemap entries
- Consolidate duplicate templates
- Stop internally linking to low-value filter combinations
- Reduce parameter-based crawl paths
- Improve category and hub structures
- Strengthen internal links to priority pages
- Use canonicals consistently
- Avoid generating indexable pages with no unique value
Once crawl paths are cleaner, important pages have a stronger chance of receiving attention.
How NytroSEO Supports Metadata Clarity And Page Relevance
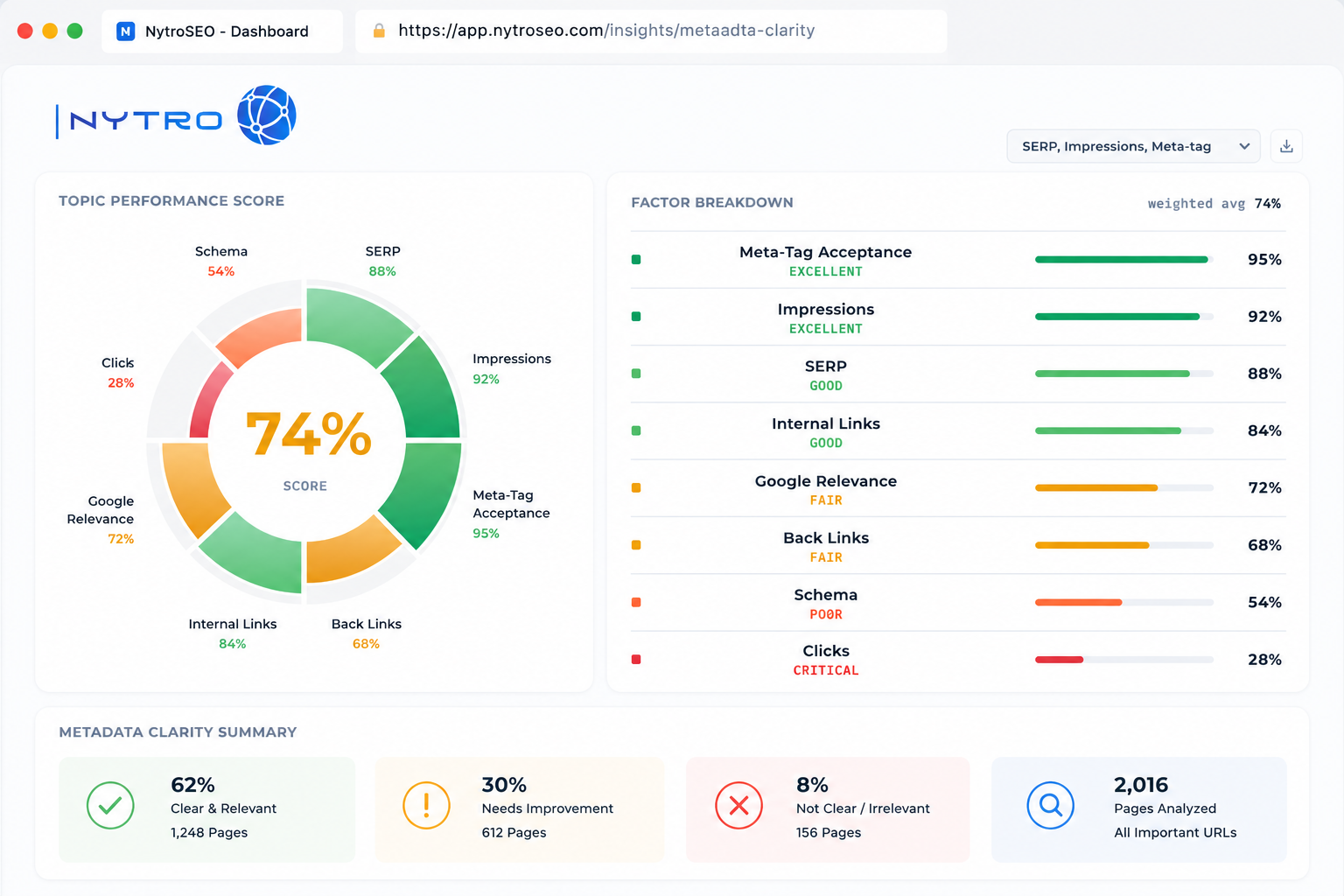
NytroSEO supports the metadata and page-relevance layer of this workflow. It does not force Google to index pages. No ethical SEO platform can guarantee indexation. NytroSEO helps improve metadata clarity, keyword-to-page relevance, and optimization focus across website pages. It uses a small JS snippet to inject optimized meta tags into the rendered website code, without modifying the CMS backend or stored content.
This is important for teams managing large websites because manual metadata work does not scale well across hundreds, thousands, or tens of thousands of pages. For crawl efficiency work, NytroSEO can help support:
- Clearer page titles for important URLs
- More relevant meta descriptions
- Better keyword-to-page alignment
- Stronger optimization focus for priority pages
- Identification of pages where metadata does not represent the page clearly
- Operational prioritization across large URL sets
Metadata alone will not solve every indexing issue. It will not fix a blocked robots rule, a noindex directive, a soft 404, a weak canonical setup, or a thin page. But unclear metadata can weaken page understanding, and better metadata can support stronger signals when combined with content, internal links, and technical cleanup. Sign up with a free account to begin.
Google Search Console Crawled Currently Not Indexed: FAQ For Search And AI Visibility
Crawl efficiency means helping search engines spend crawl resources on the URLs that matter most. It reduces wasted crawl attention on duplicate, outdated, filtered, thin, or low-value URLs and helps important pages become easier to discover, crawl, understand, and evaluate.
Google Search Console crawled currently not indexed means Google crawled the URL but did not add it to the index at that time. Important URLs with this status should be reviewed for content value, uniqueness, metadata clarity, internal linking, canonical consistency, and technical access.
Google Search Console discovered currently not indexed means Google found the URL but has not crawled it yet. This can relate to crawl prioritization, crawl demand, server load, internal linking, sitemap quality, duplicate URL patterns, or low perceived value.
Google crawl budget affects how much attention Googlebot can and wants to spend on a website. If too many low-value URLs are exposed, important pages may receive less crawl attention, be crawled later, or be evaluated less often for indexing.
To fix crawled currently not indexed pages, start by deciding whether the page should be indexed. If it is important, improve content depth, metadata clarity, internal links, canonical consistency, rendered content, structured data alignment, and search intent relevance.
To fix discovered currently not indexed pages, start by confirming whether the URL is business-critical. Then improve crawl paths, sitemap inclusion, internal links, server reliability, canonical signals, and page value.
No. Crawl efficiency cannot guarantee indexing. It can reduce crawl waste, clarify priority URLs, and give search engines stronger reasons to crawl, understand, index, rank, and reference important pages.
Modern SEO is not only about publishing more pages. It is about making sure the right pages are worth crawling, indexing, ranking, and citing.
Crawl efficiency gives SEO teams a practical way to reduce URL noise, prioritize business-critical pages, improve metadata clarity, strengthen internal links, and support better indexation signals.
The goal is not to force Google to index everything. The goal is to make the pages that matter easier to find, easier to understand, easier to trust, and easier to select for both Search and AI-powered visibility.



