
Google may not penalize weak pages in a way you can easily see. It may simply stop giving them crawl priority, leave them out of the index, and exclude them from the search and AI visibility path your business depends on.
When important URLs are stuck in Google Search Console as “Crawled, currently not indexed” or “Discovered, currently not indexed,” the issue is not only indexation. It can affect rankings, AI Overviews, AI Mode visibility, and brand citations. Crawled, currently not indexed is now a signal that crawlability, indexability, content quality, and relevance need to be reviewed together.
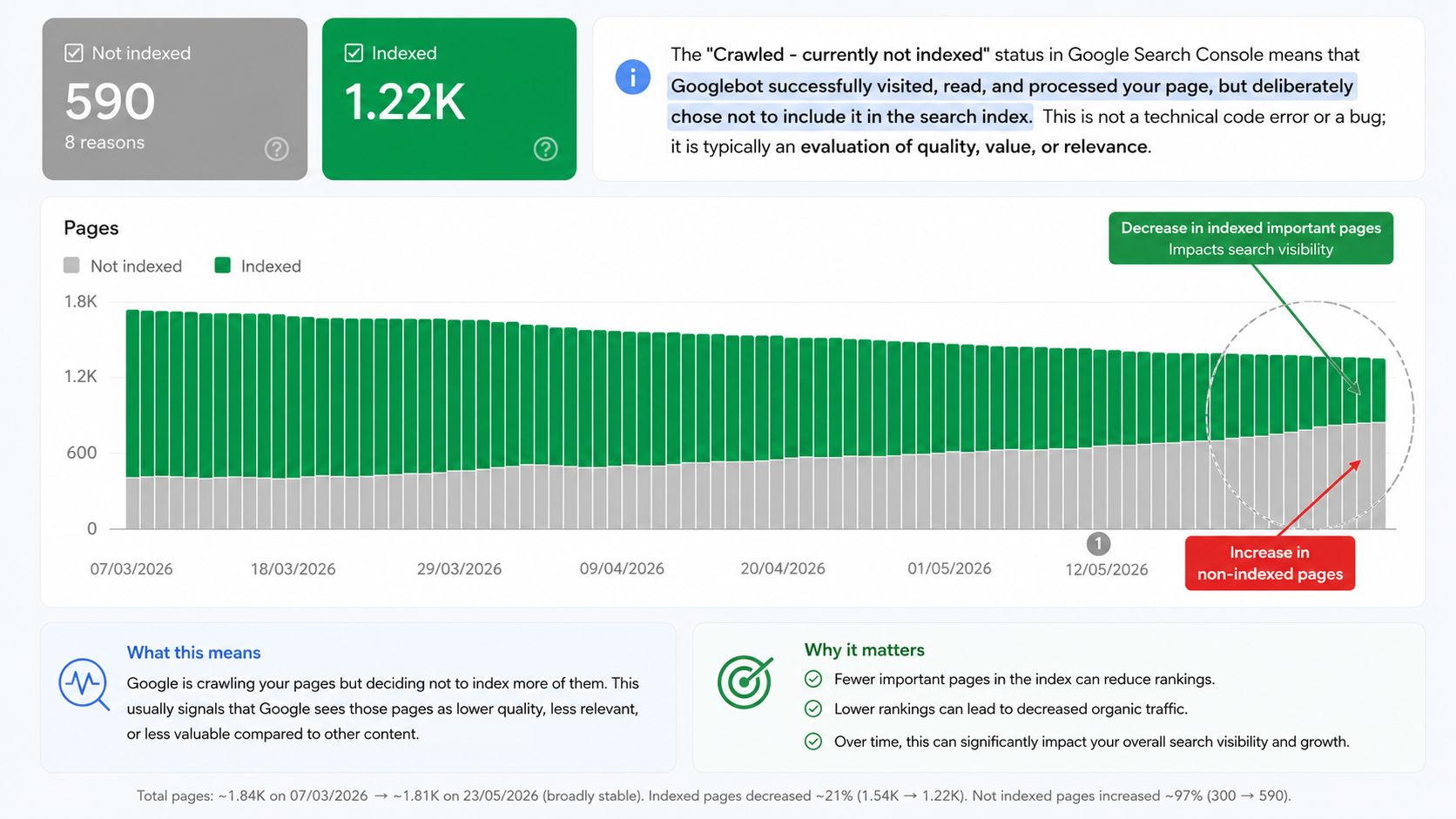
Many websites are now seeing a significant decrease in the number of crawled pages, while more URLs are appearing as non-indexed in Google Search Console. For important service pages, product pages, category pages, location pages, and strategic articles, this can directly impact search visibility, AI visibility, and the ability of your brand to be cited in AI-powered search experiences.

The timing matters. The Google May 2026 core update status shows that the rollout completed on June 2, 2026. Google’s core updates documentation explains that broad core updates are designed to improve how Search presents helpful and reliable results. At the same time, Google’s crawl and AI search guidance make the connection clearer: important pages must be crawlable, indexable, useful, and eligible if they are expected to support rankings and generative AI visibility.
Crawled But Not Indexed: Why Search Eligibility Comes First
The status “Crawled, currently not indexed” means Google crawled the page but did not add it to the index. The Google Search Console Page Indexing report explains that the page may or may not be indexed later, and there is no need to resubmit the URL only because it appears under this status.
That definition matters because many teams treat the status like a broken setting. Sometimes the cause is technical: robots rules, noindex directives, canonical confusion, soft 404s, blocked resources, rendering issues, redirect errors, or server problems. But often the issue is evaluative. Google has seen the page, processed enough of it to make a decision, and has not considered it suitable for index inclusion at that moment.
For SEO teams, the practical question is not only “How do we get this page indexed?” The better question is “Why would Google choose this page over other pages it has already crawled?” If the page is thin, duplicated, outdated, poorly connected, unclear, or too similar to other URLs, Google may crawl it and still leave it out.
This is where AI search optimization starts. A page cannot support AI visibility if it cannot first support search eligibility. If a high-value URL is crawled but not indexed, it cannot fully contribute to rankings, AI Overviews, AI Mode visibility, or brand citations.
Discovered Currently Not Indexed: When Google Knows The URL But Has Not Crawled It
 The status “Discovered, currently not indexed” is different. Google’s documentation explains that this means the page was found but not crawled yet. In many cases, Google wanted to crawl the URL but rescheduled the crawl, often because crawling was expected to overload the site.
The status “Discovered, currently not indexed” is different. Google’s documentation explains that this means the page was found but not crawled yet. In many cases, Google wanted to crawl the URL but rescheduled the crawl, often because crawling was expected to overload the site.
This status is usually about discovery and prioritization. Google knows the URL exists through a sitemap, internal link, external link, feed, canonical reference, or another discovery path. But knowing a URL exists does not mean Google will immediately spend crawl resources on it.
The most common mistake is mixing discovered pages and crawled pages into the same problem list. They represent different stages. A discovered URL may need stronger internal linking, sitemap clarity, crawl path improvement, or reduced URL noise across the website. A crawled URL may need stronger content, clearer metadata, better differentiation, or technical cleanup.
For large websites, ecommerce stores, marketplaces, directories, travel sites, SaaS help centers, and programmatic SEO sites, this distinction becomes critical. A site can generate thousands of discoverable URLs without giving Google enough reason to crawl, index, or rank them.
Crawl Budget SEO: Why Crawl Attention Is Now A Visibility Issue
Crawl budget SEO is no longer only a topic for very large websites. It is becoming relevant to any site where important URLs compete with weak, duplicate, outdated, filtered, parameter-based, or low-value URLs.
Google’s crawl-budget guidance explains that crawl budget is determined by crawl capacity and crawl demand. Crawl capacity relates to what Google can crawl without overwhelming your server. Crawl demand relates to what Google wants to crawl, influenced by factors such as site size, update frequency, page quality, relevance, perceived inventory, popularity, and staleness.
This creates a practical SEO problem. If your site exposes too many URLs that do not deserve to be crawled, Google may spend attention in the wrong areas. Google specifically warns that duplicate, removed, or unimportant URLs can waste crawling time. It also recommends managing URL inventory, consolidating duplicate content, keeping sitemaps updated, avoiding long redirect chains, and eliminating soft 404 errors.
The strongest crawl strategy is not to demand that Google crawl everything. The better strategy is to make your most valuable URLs easier to find, easier to understand, and easier to justify as index-worthy. When crawled, currently not indexed appears across important pages, crawl efficiency, content quality, and page relevance should be reviewed together. See our webinars for a deeper walkthrough.
Crawl Budget Google: How Googlebot Decides What Deserves Attention
Crawl budget Google behavior is shaped by choices. Google has limited crawling resources, and its guidance is clear that crawl budget is the set of URLs Google can and wants to crawl.
This means your website’s URL inventory sends a strong signal. A clean site with clear navigation, useful pages, updated sitemaps, strong internal links, and differentiated content gives Googlebot a better path. A noisy site with endless filters, duplicate parameters, weak tags, outdated archives, and thin templates gives Googlebot more work with less reward.
For example, an ecommerce site may have one useful category page and hundreds of filtered variations. A travel website may have thousands of location pages with only small wording changes. A SaaS help center may have old support pages that no longer match the current product. A blog may have tag pages that repeat the same post lists without unique value.
In each case, the issue is not only page volume. The issue is signal quality. Googlebot has to decide which URLs deserve attention. The more your site exposes low-value URLs, the harder it becomes to focus crawl attention on pages that drive revenue, leads, product discovery, or authority.
Crawl Budget Optimization: Fix The System, Not Only The URL
Crawl budget optimization starts with segmentation. Not every non-indexed URL deserves repair. Some URLs should remain out of the index. Internal search pages, thin tag pages, duplicate filters, sort URLs, staging URLs, expired offers, cart pages, and soft 404s are often better controlled, consolidated, blocked, redirected, or removed.
The real opportunity is to separate your URLs into groups. High-value pages include service pages, product pages, category pages, location pages, lead-generation pages, pricing pages, and strategic articles. Supporting pages include help articles, comparison pages, FAQs, case studies, documentation, and educational content that supports authority. Low-value or duplicate pages include filters, parameters, thin tags, alternate versions, empty categories, duplicate templates, and outdated pages.
Once URLs are grouped, decisions become clearer. Important pages should be strengthened. Supporting pages should be connected. Duplicate pages should be consolidated. Low-value pages should stop consuming unnecessary attention. This approach is more efficient than trying to fix every URL equally.
A practical audit should answer four questions: should this URL be indexed, can Google crawl it efficiently, does the page provide enough unique value, and does the page send clear signals about its purpose?
Crawled But Currently Not Indexed: Quality, Clarity, And Relevance Signals
The phrase crawled but currently not indexed is often used by site owners to describe pages that Google has already seen but not stored in the index. In practice, this status often points to one or more weak signals.
Content may be too thin. The page may not provide enough information, examples, proof, product details, or original value. It may be a short page created only to target a keyword.
Content may be too similar. The page may repeat the same product copy, city-page template, category text, tag-page pattern, or article summary used elsewhere on the site.
The page may be poorly connected. If your own website barely links to the page, Google may not interpret it as important. Internal links, breadcrumbs, navigation modules, related content blocks, and contextual anchors all help communicate priority.
Metadata may be unclear. Titles, descriptions, headings, image alt text, and internal anchor text should accurately explain what the page is about and why it matters. Weak metadata does not always cause exclusion, but it can make the page harder to classify and less compelling as a search result.
A crawled, currently not indexed solution should therefore start with diagnosis. Check whether the page deserves to be indexed, whether it is unique, whether it is internally supported, whether it matches search intent, and whether it sends clear enough signals for Google to understand its value. Sign up with a free account to get started.
SEO Crawl Budget: How Metadata And Internal Links Support Index Readiness
SEO crawl budget work is not only about robots.txt files, sitemaps, and server response codes. Those matter, but they are not the full picture. A page also needs enough contextual support to make its role obvious.
Metadata helps define the page’s purpose. A strong title explains the topic and intent. A strong meta description clarifies value and expected relevance. Headings structure the answer. Image alt text describes visual assets. Internal anchor text tells search engines how other pages describe the target URL.
Internal links help define importance. Pages linked from the homepage, primary navigation, category pages, related resources, and high-authority articles are easier to discover and interpret. Orphan pages, deeply buried pages, and pages linked only from low-value templates often struggle to earn attention.
This is where NytroSEO can support optimization work. NytroSEO uses a small JS snippet to inject optimized meta tags into the rendered website code, without modifying the CMS backend or stored content. The goal is to improve metadata clarity, keyword-to-page relevance, and optimization focus across important website pages. It pairs naturally with adaptive SEO automation and broader SEO automation workflows.
No tool can force Google to index a page. The practical value is making important pages clearer, more relevant, and better aligned with search intent so they have stronger reasons to be crawled, understood, indexed, and ranked.
Crawled Not Currently Indexed: Why AI Visibility Depends On Index Eligibility
The phrase crawled not currently indexed is another way teams describe the same practical issue: a page exists, Google has interacted with it, but the page is not fully participating in search visibility.
Google’s AI search guidance explains that AI Overviews and AI Mode are rooted in Google’s core Search ranking and quality systems and rely on content from Google’s Search index. Google also says that, to be eligible for generative AI features, a page must be indexed and eligible to appear in Search with a snippet.
That creates a simple chain: crawlable pages can be discovered, indexed pages can become eligible for Search, eligible pages can support traditional rankings, and strong indexed content can support AI Overviews, AI Mode, and brand citations.
A page with this status breaks this chain. It may still exist for users, but it cannot fully support the visibility path that matters for SEO, AEO, GEO, or AI search readiness. This does not mean every page must be indexed. It means important pages must earn index eligibility.
Discovered But Not Indexed: How To Prioritize What Deserves Attention
The phrase discovered but not indexed is often used informally, but it usually points to a page Google knows about before it has been fully crawled and evaluated. The response should be prioritization, not panic.
Start with business value. Which discovered URLs represent revenue, leads, product discovery, brand authority, or strategic content? Those should move to the front of the queue.
Then check crawl paths. Are the URLs in XML sitemaps? Are they linked from important pages? Are they buried too deep? Are they generated only through filters or scripts? Do they appear in navigation, breadcrumbs, category structures, or related content modules?
Next, check URL inventory. If thousands of weak URLs are discoverable, important pages may be competing with noise. Reducing duplicate filters, cleaning up tags, consolidating thin variants, and improving canonical signals can help Google focus on better candidates.
Finally, check page value before requesting indexing. Requesting indexing for a weak page does not solve the underlying problem. The page needs to deserve inclusion.
Crawl Budget Optimization: A Practical Checklist For Important URLs
Use this checklist before deciding whether a non-indexed page needs work.
- Check index intent. Should this page appear in Search as a standalone result?
- Check technical access. Does the page return a clean 200 status, avoid noindex, avoid accidental robots blocking, render meaningful content, and use a consistent canonical?
- Check uniqueness. Does the page offer information, proof, examples, products, services, or insights that are not simply copied from another URL?
- Check internal links. Is the page linked from relevant, important pages? Does the anchor text clarify its purpose?
- Check metadata clarity. Do the title, description, headings, and page summary accurately describe what the page is about?
- Check content quality. Does the page satisfy user intent better than competing pages? Does it answer real questions with current, useful, trustworthy information?
- Check URL inventory. Is the site exposing large volumes of low-value URLs that could waste crawl attention?
- Check monitoring. Are you tracking the affected URLs over time in Search Console, crawl stats, rank data, and traffic reports?
When crawled, currently not indexed affects important URLs, the fix is usually a combination of technical cleanup, content improvement, internal linking, metadata clarity, and prioritization.
Crawl Budget SEO: What This Means For The Webinar
The webinar connected to this topic focuses on one practical question: how do you identify which non-indexed pages are normal, which ones are harmful, and which ones deserve immediate action?
You will learn how to separate technical errors from quality issues, how to evaluate crawl budget waste, how to read Google Search Console indexing patterns, and how to decide whether the problem is crawlability, indexability, content quality, internal linking, metadata clarity, or page relevance.
The key point is simple: no tool can guarantee indexing. But a stronger technical and content foundation can give Google better reasons to crawl, understand, index, rank, and reference the pages that matter.
For agencies, ecommerce teams, SaaS companies, publishers, and large-site owners, this is now an operational discipline. Search visibility and AI visibility are no longer separate tracks. They both depend on whether important pages are accessible, useful, understandable, and eligible.
SEO Crawl Budget: Final Takeaway
Modern SEO is no longer only about creating more pages. It is about making sure the right pages are worth crawling, indexing, ranking, and citing.
The search and AI visibility path starts with crawlability, but it does not end there. Pages must be technically accessible, useful, unique, internally supported, clearly described, and relevant to real user intent.
Treat crawled, currently not indexed as a signal to improve the system around your important pages. Reduce crawl waste. Strengthen useful content. Improve metadata clarity. Support priority URLs with internal links. Align pages with search intent. Monitor the results.
The goal is not to force Google to index everything. The goal is to make the pages that matter easier to crawl, easier to understand, easier to trust, and easier to select for both Search and AI-powered visibility.
Google Search Console Crawled Currently Not Indexed: Q&A For SEO And AI Visibility
Google search console crawled currently not indexed means Google crawled the URL but did not add it to the index at that time. The official status is commonly shown as Crawled – currently not indexed, and important pages with this status should be reviewed for quality, relevance, duplication, internal linking, canonical signals, metadata clarity, and technical accessibility.
No. Google crawl budget should be focused on important URLs, not every non-indexed page. Some URLs should not be indexed, including duplicate pages, blocked pages, noindex pages, 404s, internal search pages, and low-value utility URLs. The priority is to make sure important pages can be crawled, understood, and indexed.
Google search console discovered currently not indexed means Google found the URL but has not crawled it yet. This is different from Google search console crawled currently not indexed, where Google already fetched the page but did not index it. Discovered URLs often require review of crawl priority, internal linking, sitemap quality, server behavior, and URL inventory.
Metadata can help support efforts to fix crawled currently not indexed pages, but it does not force indexing. Clear titles, descriptions, headings, image alt text, and internal anchor text can help search engines better understand page relevance, page purpose, and optimization focus.
Crawled not currently indexed pages have limited ability to support AI visibility because important pages must be crawlable, indexable, understandable, and useful. If a page is not indexed and eligible to appear in Search, it cannot fully support generative AI visibility, AI Overviews, AI Mode, or brand citations.



